Enterprise adoption of Retrieval-Augmented Generation has moved beyond pilot projects. Many organizations already use internal chatbots, document assistants, and AI search tools. The next priority is scaling these systems across business operations. Managers now demand productivity improvements, data governance, quicker access and a return on investment.
That shift changes priorities. During the MVP stage, teams usually ask whether the solution functions as expected. In production, they evaluate response speed at scale, permission controls, operating cost, and how well it fits existing business workflows without causing delays or process issues.
A prototype can appear successful with a few hundred documents and a small pilot group. Production environments are more demanding. They involve multiple data systems, thousands of users, changing content, legal controls, uptime expectations, and strict ROI scrutiny. This is why many high-performing proof-of-concept deployments stall before reaching enterprise-wide deployment.
This guide explains how companies move from MVP to full production with a practical execution model. It is designed for decision-makers evaluating Enterprise RAG solutions, RAG platform deployment, MVP development services, or long-term retrieval-augmented generation development programs.
What does an Enterprise RAG System do?
Retrieval-Augmented Generation technology merges language models with retrieval engines which look up relevant business data and then create a response. Rather than just responding to queries with pre-programmed information, Retrieval-Augmented Generation systems take into account up-to-date internal information.
That model is useful because enterprise knowledge changes constantly. Policies are updated, product details change, support fixes evolve, and internal procedures shift. A static model cannot reliably reflect those changes. Retrieval solves that problem by referencing current sources.
In real applications, enterprise RAG systems integrate with document management systems, CRM systems, help desks, internal wiki pages, contract databases, and other databases. Questions are posed in plain English, and responses are generated using information from reliable sources.
Typical use cases include:
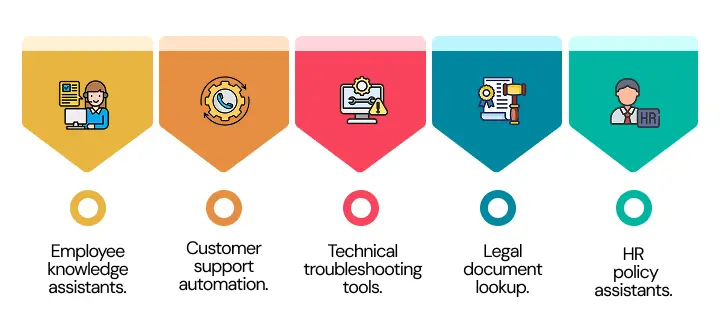
- Employee knowledge assistants.
- Customer support automation.
- Technical troubleshooting tools.
- Legal document lookup.
- HR policy assistants.
McKinsey has reported that generative AI can add significant productivity value across enterprise functions, especially where knowledge retrieval and content workflows are common. That is one reason RAG has become a critical business priority.
Prefer Reading: How To Build A Production-Grade RAG Platform In 2026 Architecture And Stack
Why Many RAG MVPs Never Reach Production?
The most common failure point is not the model. It is the surrounding operating system.
Many MVPs are built using whatever documents are easiest to access. The list may include out-of-date PDFs, duplicates, inconsistent names, and lack of meta data. The retrieval results become poor if the source data is bad. Users then question system reliability because response accuracy becomes inconsistent.
Another common issue is the lack of structured testing. Teams may ask a handful of demo questions and receive acceptable answers. Real users then submit hundreds of queries with acronyms, shorthand language, product codes, and edge cases. Without a benchmark dataset, relevance problems remain hidden until rollout.
Security is another major blocker. Permissions are sometimes delayed until later phases, but enterprise deployments need access controls from the start. A single incident involving restricted finance, HR, or legal data can stop momentum immediately.
Cost also becomes visible after early success. Premium models, large prompt sizes, repeated indexing, and no caching can inflate operating spend rapidly.
Frequent reasons pilots stall include:
- Low-quality source data quality.
- Missing ownership model.
- No retrieval evaluation process.
- Poor access controls.
- Undefined ROI metrics.
- Rising monthly costs.
Organizations that recognize these issues early usually move faster than those treating them as post-launch fixes.
Stage 1: Build the Right MVP First
A scalable MVP should prove business value quickly. It should not attempt to solve every use case at once.
The best starting point is one expensive workflow. If support agents spend too much time searching for answers during live calls, solve that problem first. If engineers waste hours locating version-specific documentation, start there. If employees repeatedly email HR for policy clarifications, that is another strong candidate.
Focused use cases create measurable wins. Broad use cases create vague feedback and slow execution.
It is also smart to limit the first data sources. Starting with one to three trusted systems reduces ingestion complexity and improves testing quality. A narrow launch often produces better adoption than a wide launch with low-quality responses.
Metrics should be agreed upon before development begins. Good examples include answer accuracy, search time reduction, response latency, and pilot adoption rate.
A disciplined MVP often includes:
- Retrieval layer.
- Vector search or hybrid search.
- Model gateway.
- Basic analytics.
- Feedback capture.
- Admin controls.
This is where structured MVP development solutions help. Experienced teams know how to build only what is needed for validation while keeping a production path open.
A trusted MVP product development agency can also reduce prototype debt by using scalable architecture from the first release.
Stage 2: Improve Retrieval Before Expanding Users
Many enterprises add users too early. If retrieval quality is inconsistent, a larger rollout simply spreads dissatisfaction faster.
The better approach is to build a benchmark test set using real internal questions. These should come from support logs, search records, helpdesk requests, and employee communication channels. That gives a realistic picture of how users actually ask questions.
Each test cycle should measure whether the correct document was retrieved, whether the right section ranked highly, whether the answer was complete, and whether latency stayed within target limits.
Chunking strategy matters more than many teams expect. If documents are split too aggressively, context is lost. If chunks are too large, ranking precision falls. Contracts, manuals, policies, and product specs often need different chunking logic.
Hybrid retrieval is increasingly common because semantic search alone may miss exact codes, legal phrases, or industry acronyms. Combining keyword relevance with vector search usually improves reliability.
Retrieval improvement areas often include:
- Better chunk sizing.
- Metadata tagging.
- Keyword plus vector ranking.
- Freshness scoring.
- Reranking models.
- Source citations.
When users can verify where an answer came from, trust rises significantly.
Stage 3: Build Production Architecture
Once answer quality is stable, architecture becomes the next priority.
Connecting the pipeline to various tools used by the company such as SharePoint, Salesforce, Jira, Confluence, ServiceNow, SQL database, and cloud-based storage are essential. There will be continuous changes in the internal data, therefore, the pipeline must adapt to these changes.
That usually requires scheduled syncs, change detection, duplicate removal, metadata enrichment, and parsing support for multiple file formats. Some organizations also need OCR for scanned documents and image-heavy PDFs.
The retrieval layer must be fast under load. Many enterprises combine vector indexes with keyword indexes and reranking services to balance relevance and speed.
The model layer should also be tiered. Smaller models often handle summaries, routing, and simple requests at lower cost. Larger models should be reserved for reasoning-heavy tasks where quality gains justify higher spend.
Core production layers often include:
- Source connectors.
- Ingestion pipeline.
- Search indexes.
- Model gateway.
- API layer.
- Monitoring dashboard.
- Admin controls.
The delivery interface matters as well. Tools are adopted more readily by employees who operate within existing platforms such as Microsoft Teams, Slack, corporate intranets, or product dashboards.
What are the Security and Governance Requirements?
Security should be embedded from the beginning, not added later.
The authentication mechanism is often provided by identity providers such as the Azure AD, Okta or Google Workspace. The permissions that are in place should be reflected in the role-based access in such a way that users can only receive the content they have access to.
Encryption should cover stored data and data in transit. Administrative actions should be logged. Sensitive prompts and outputs may also require retention policies depending on industry requirements.
Auditability is increasingly important. Enterprises often need to know who asked what question, what sources were retrieved, and which model generated the response.
Common governance requirements include:
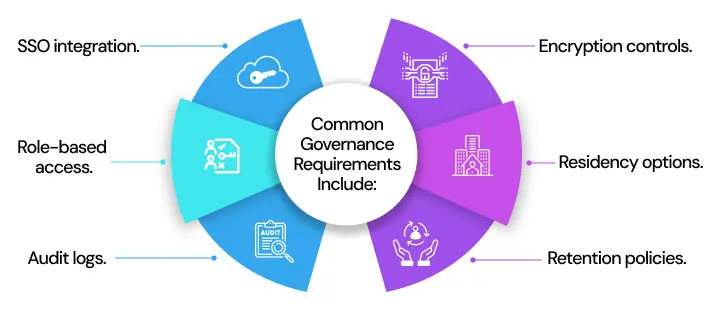
- SSO integration.
- Role-based access.
- Audit logs.
- Encryption controls.
- Residency options.
- Retention policies.
IBM has reported multi-million-dollar average breach costs globally, which explains why governance receives strong executive attention during AI deployments.
This is also why many organizations choose Custom AI Solutions instead of generic consumer-grade tools.
Performance and Cost at Scale
A system with fifty users behaves differently from one serving five thousand employees.
Once adoption rises, latency becomes visible immediately. Users expect fast responses, especially when replacing search workflows. Many organizations aim for median responses in a few seconds and stable uptime for business-critical use cases.
Performance improvements often come from caching common queries, streaming partial responses, autoscaling infrastructure, and sending only relevant context to the model.
Cost control is equally important. AI budgets can rise quickly when premium models are used for every request or when prompts include redundant context.
Strong cost management usually includes:
- Model routing by task complexity.
- Caching repeated answers.
- Incremental indexing.
- Prompt token limits.
- Usage monitoring.
- Archive low-value data.
Well-run deployments often reduce monthly spend materially after routing and caching improvements.
Measuring ROI in Terms Leadership Understands
Executives fund measurable outcomes, not technical novelty.
For internal knowledge systems, time saved is often the clearest metric. If employees previously spent ten minutes locating answers and now spend two, the productivity gain compounds quickly across large teams.
Support leaders may focus on reduced handle time, faster first response, lower escalations, or ticket deflection. Sales leaders may care about faster proposal generation and easier access to approved content.
A practical example shows the scale. If 1,000 employees save twelve minutes per day, that equals 200 hours saved daily. Across twenty workdays, that becomes roughly 4,000 hours each month.
Useful ROI indicators include:
- Search time reduction.
- Ticket deflection rate.
- Faster onboarding.
- Lower escalation volume.
- Employee adoption rate.
- Cost per resolved query.
Numbers like these help sustain executive support.
Why NetSet for Enterprise RAG Deployment?
NetSet Software helps enterprises move from RAG pilots to secure, scalable production systems. Many businesses build MVPs but face challenges with retrieval quality, system integrations, governance, and adoption. Our team solves these gaps with execution-focused AI development services built for enterprise use.
We deliver Retrieval augmented generation solutions with secure data pipelines, fast search architecture, and Custom integrations across CRMs, internal portals, cloud storage, support tools, and collaboration platforms. This helps teams use AI within existing enterprise workflows.
For successful Enterprise deployments, we prioritize Production governance through role-based access, audit logs, encrypted data flows, monitoring, and scalable infrastructure.
Prefer Reading: Retrieval Augmented Generation (RAG): A Guide To Understand Everything In Detail
Conclusion
The move from MVP to production is where enterprise RAG programs are truly tested.
A pilot proves that the concept can work. Production proves that it can work securely, accurately, quickly, and economically at scale. That requires discipline across architecture, retrieval quality, governance, and business measurement.
Organizations that succeed usually follow a repeatable path. They start with one costly problem. They validate outcomes early. They improve retrieval before broad rollout. They control costs as usage grows. They treat governance as a design requirement.
That is how durable RAG solutions are built. It is also how Retrieval augmented generation solutions continue receiving executive support long after the pilot phase ends.

FAQs
How long does it take to launch an enterprise RAG MVP?
Most focused enterprise MVPs take four to eight weeks when scope is controlled and data access approvals move quickly. Projects usually take longer when multiple systems require cleanup, integration reviews, or legal approval.
What usually blocks RAG systems from reaching production?
The largest blockers are low data quality, missing access controls, weak retrieval testing, and unclear ownership. In many cases, the model performs adequately, but the enterprise operating model is not ready.
Can RAG use private internal company data safely?
Yes, when deployed correctly. Secure connectors, inherited permissions, encryption, logging, and hosting controls allow enterprises to use private internal data while maintaining governance and security requirements.
Do enterprises need custom development for RAG?
Many do. Standard tools rarely match legacy systems, approval workflows, compliance needs, and department-specific processes. That is why many organizations invest in Custom AI Solutions for production deployments.
How do companies reduce RAG operating costs over time?
They reduce costs through model routing, caching repeated answers, tighter prompt context, incremental indexing, and continuous usage monitoring. Mature teams optimize cost per request as adoption expands across departments.